Lo primero que veremos,
qué es un shell; después, qué es una gramática, cuando una
gramática se clasifica como LL1 (y si no lo es como llevarla) y por
último veremos una pequeña implementación en C de un shell.
Shell:
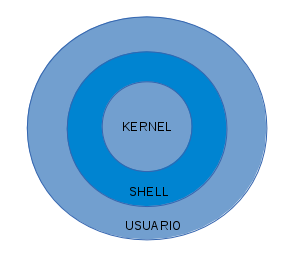
Shell (del inglés cascarón, coraza, concha, etc) toma este nombre
por ser el shell una interfáz entre el nucleo del Sistema Operativo
y el usuario, es un intérprete a través del cual este le da
órdenes(ver Fig 1).
 |
| Fig 1. |
El shell es un programa
capaz de interpretar comandos, hacer una petición al sistema y
devolver un resultado. Exixsten varias implementaciones: sh,
bash,
csh, Tcsh, …, etc... Cada usuario tiene una shell predeterminada
ej:
adacosta:x:1008:1008:PEPSI,,,:/home/adacosta:/bin/bash
el cual es ejcutado al
autenticarse el usuario en una terminal, o al abrir una emulador de
terminal en una sesión
X11, lo primero que hace el shell es leer sus configuración de
sistema (/etc) y después leer la configuración del usuario
(/home/user-name/.*)
pudiendo llegar a ser uno o varios archivos, en mi caso:
(
/home/adacosta/.bashrc,
/home/adacosta/.profile /home/adacosta/.bash_*)
Gramática:
Intuitivamente, una gramática es un conjunto de reglas para formar
correctamente las frases de un lenguaje; así ́ tenemos la
gramática del español, del francés, etc. Según N. Chomsky existen
4 tipos fundamentales de gramáticas:
1.
Gramáticas regulares, o de tipo 3: Las reglas son de la forma
A → α B o bien A → α, donde A y B son variables (no terminales)
y α es una constante (terminal). Estas gramáticas son capaces de
describir los lenguajes regulares.
́
2.
Gramáticas Libres de Contexto (GLC), o de tipo 2: Las reglas
son de la forma X → α, donde X es una variable y α es una cadena
que puede contener variables y constantes. Estas gramáticas producen
los lenguajes Libres de Contexto.
́
3.
Gramáticas sensitivas al contexto (dependientes del
contexto) o de tipo 1: Las reglas son de la forma αAβ → αΓβ,
donde A es una variable y α, β y Γ son cadenas cualesquiera que
pueden contener variables y constantes.
4.
Gramáticas no restringidas, o de tipo 0: Con
reglas de la forma α → β, donde α no a puede ser vacío, que
generan los lenguajes llamados “recursivamente enumerables”.
Los
objetivos de una gramática son: definir las sentencias que pertenece
a un lenguaje, así como describir estructuralmente dichas
sentencias. Las gramáticas generan sentencias mediante secuencias de
derivaciónes directas
Como
ejemplo veamos una gramática subconjunto del idioma español:
G = (
{<frase>, <sujeto>, <predicado>, <artículo>,
<sustantivo>, <verbo>},
{el, la, perro, luna, brilla, corre}, P, <frase>)
P:
<frase>
→ <sujeto> <predicado>
<sujeto>
→ <artículo> <sustantivo>
<artículo>
→ el | la
<sustantivo>
→ perro | luna
<predicado>
→ <verbo>
<verbo>
→ brilla | corre
En
correspondencia con esta gramática podriamos generar frases como las
que siguen.
{el
perro corre , el perro brilla, la perro brilla, ...}
estando todas ellas correctas sintácticamente aunque haciendo un
análisis semántico (en otra etapa) podriamos detectar que algunas
de las frases carecen de sentido.
Gramáticas
LL1:
Un analizador LL es llamado un analizador LL (k) si usa k tokens
cuando el analizador ve hacia delante de la sentencia. Si existe tal
analizador para cierta gramática y puede analizar sentencias de esta
gramática sin marcha atrás, entonces es llamada una gramática LL
(k). De estas gramáticas, la gramática LL(1), aunque es bastante
restrictiva, esta es muy popular (principalmente en actividades
docentes) porque los analizadores LL correspondientes sólo necesitan
ver el siguiente token para hacer el análisis de sus decisiones.
Lenguajes mal diseñados usualmente suelen tener gramáticas con un
alto nivel de k, y requieren un esfuerzo considerable al analizar.
Una gramática ambigua es aquella que produce más de una derivación
más a la izquierda o más de una derivación más a la derecha para
la misma sentencia. En general existen tres estrategias iniciales
para eliminar la ambiguedad de las gramáticas, ellas son:
1. Definir la precedencia y asociatividad de los
operadores.
2. Eliminar la recursividad izquierda o derecha.
3. Factorizar.
Veamos un ejemplo:
G = ({<Expresión>}, {id, +, - , *, / , (,
)}, P, <Expresión>)
P:
(1) <Expresión> → <Expresión> + <Expresión> |
<Expresión> - <Expresión>
(2) <Expresión> → <Expresión> * <Expresión> |
<Expresión> / <Expresión>
(3) <Expresión> → id | ( <Expresión> )
Precedencia y
asociatividad:
Definamos un nivel de prioridad para cada operador como sigue:
1. (), id
2. *, /
3. +, -
Nivel 1 Se introduce un nuevo símbolo No Terminal, que llamaremos
<Factor> para describir una expresión indivisible y con
máxima precedencia.
<Factor> → id | ( <Expresión> ) .
Nivel 2 Se introduce un nuevo símbolo No Terminal, que llamaremos
<Término>, que generará una secuencia de uno o más términos
generados por el No Terminal <Factor>, conectados con los
operadores de nivel precedencia 2.
<Término> → <Término> * <Factor> | <Término>
/ <Factor> | <Factor>
Nivel 3 Se mantiene el símbolo No Terminal <Expresión> para
describir secuencias de uno o más términos generados por el No
Terminal <Término>, conectados con los operadores de nivel
precedencia 3.
<Expresión> → <Expresión> + <Término> |
<Expresión> - <Término> | <Término>
Aplicando las reglas anteriores la gramática definida anteriormente
queda re definida como sigue:
G = ({<Expresión>, <Término>, <Factor>},
{id, +, - , *, / , (, )}, P, <Expresión>)
P:
<Expresión> → <Expresión> + <Término> |
<Expresión> - <Término> | <Término>
<Término> → <Término> * <Factor> | <Término>
/ <Factor> | <Factor>
<Factor> → id | ( <Expresión> )
Recursividad
Izquierda :
Una producción de la forma A → Aβ se dice que es recursiva
inmediata. Para eliminar las recursividades inmediatas podemos seguir
el procedimiento siguiente:
1. Se agrupan las A-producciones:
A→ Aα1 | Aα2 | . . .| Aαm | β1 | β2 . . .| βn
donde ningún βi comienza con A.
2. Se reemplazan las A-producciones por:
A→ β1 A’| β2 A’| . . .| βn A’
A’→ α1 A’| α2 A’| . . .| αm A’| ǫ
Aplicamos el procedimiento anterior para eliminar la recursividad
directa en la gramática:
G = ({<Expresión>, <Término>, <Factor>}, {id, +,
- , *, / , (, )}, P, <Expresión>)
P:
<Expresión> → <Expresión> + <Término> |
<Expresión> - <Término> | <Término>
<Término> → <Término> * <Factor> | <Término>
/ <Factor> | <Factor>
<Factor> → id | ( <Expresión> )
Para ellos seleccionamos las reglas que son recursivas directa a la
izquierda estas son:
(I) <Expresión> → <Expresión> + <Término> |
<Expresión> - <Término> | <Término>
(II) <Término> → <Término> * <Factor> |
<Término> / <Factor> | <Factor>
Aplicando la regla para la eliminación de ambiguedad 2 sobre (I) y
(II) nos queda:
<Expresión> → <Término> <MasExpresión>
<MasExpresión> → + <Término> <MasExpresión> |
- <Término> <MasExpresión> | E
<Término> → <Factor> <MasTérmino>
<MasTérmino> → * <Factor> <MasTérmino> | /
<Factor> <MasTérmino> | E
Factorización
por la izquierda.
La Factorización por la izquierda tiene el objetivo de reescribir
las producciones de la gramática con igual comienzo para retrasar la
decisión hasta haber visto lo suficiente de la entrada como para
elegir la opción correcta. El procedimiento es simple. Si tenemos
una regla de producción de la forma:
́ A → αβ1 | αβ2 | . . . | αβn | δi
esta se transforma en las regla.
A → α A′ | δi
A ′ → β1 | . . . | βn
A manera de ejemplo consideremos la regla de producción siguiente:
<Instruciones > → <Instrucción> ; <Instruciones >
| <Instrución>
Aplicando la Factorización por la izquierda nos quedan las reglas
equivalentes:
<Instruciones > → <Instrucción> <MasInstrucciones >
<MasInstrucciones > → ; <Instruciones > | E
A modo de conclusión podemos decir que las gramáticas constituyen
la mejor vía para la descripción sintáctica de los lenguajes de
programación. Existen diversas razones que justifican tal
afirmación:
Las gramáticas brindan una especificacion sintáctica precisa de los
lenguajes de programación.
Para ciertas clases de gramáticas pueden construirse analizadores
sintácticos eficientes que determinan si el programa fuente está
bien escrito. El proceso de construcción del parser puede además,
revelar ambiguedades sintácticas no detectadas en la fase de diseño
del lenguaje .
Una gramática bien diseñada puede ayudar a la traducción del
programa fuente en código objeto y a la detección de errores.
Se pueden añadir nuevas construcciones al lenguaje de forma fácil.
Un
ejemplo de implementación:
Un
ejemplo de implementación de un intérprete basado en un gramática
LL1 lo puede tomar clonando denishell(git
clone https://github.com/denisacostaq/denishell),
toda
la documentación relevante forma parte del código fuente y/o de la
documentación(valga la redundancia) generada con doxygen, en
especial fijarse en el comando cd, en la manera que se
“simula”
la implementació de un pipe (char**
run_pipe_on_node (struct ast_node *ast);),
en
la pesatña examples de dicha documentación puedes aprender cómo
comunicar dos procesos con un pipe real, y además
puedes ver algunos de los comandos a
ejecutar,
tambié
revisar
char** cat_args();
y char** ls_args
(); para
tener detalles sobre la internacionalización (deni-sh_i18n.h).