Los
procesadores
diseñados
en la actualidad conciben el uso de múltiples núcleos en un solo
chip, están presentes en la mayoría de los dispositivos como smartphones,
tablets,
laptops,
PCs,
videoconsolas
y muchos otros dispositivos, realmente se han abaratado mucho los
costos de estos productos al punto que hoy se han vuelto soluciones
de propósito general reemplazando el diseño original de un solo
núcleo y teniendo los fabricantes en la mira los procesadores
multinucleo que se han vuelto los nuevos
reyes
del mercado, esta competencia ha puesto en manos del usuario final
más poder de computo que nunca antes. La
arquitectura multinucleo es el diseño que pone múltiples
procesadores en un solo encapsulado o chip,
cada procesador es llamado core o núcleo, este diseño es conocido
como CMP(Chip Multiprocessors), aunque también
se conocen por CMP los procesadores hyperthreaded, que son chips con
un solo núcleo que permiten la ejecución de dos o más tareas
ejecutándose en un
mismo procesador debido a que tienen algunas partes de su hardware
duplicadas lo que permite simular
el procesador como si tuviese varios núcleos pero en realidad es un
solo procesador capaz de
ejecutar varios hilos al mismo tiempo,
en lo que nos interesa en este post, desarrollo de software,
entenderemos por CMP a procesadores capaces de ejecutar varias tareas
al mismo tiempo independientemente de la estructura interna del
hardware.
El
principal problema de esto es que el software tradicional
que se diseñaba para ejecutarse de forma secuencial y
debe ser rediseñado para explotar al máximo estas nuevas
capacidades del hardware. Para
entender mejor esto, delineemos
algunos
conceptos que son necesarios dominar.
Programa:
Este
es un conjunto de instrucciones detallando tareas a ejecutar sobre
datos o recursos de manera general, puede ser ejecutado por el CPU
directamente para los lenguajes compilados
como C, C++, GO entre otros o puede ser ejecutado
por una máquina virtual o intérprete, lo más importante es que el programa es un producto del programador.
Proceso:
Proceso:
Un proceso es básicamente un programa en ejecución, los sistemas operativos(SO) actuales bien pueden tener varias instancias de programas ejecutándose o sea varios procesos que pueden llegar a cientos o miles. Un proceso tiene su propio espacio de direcciones, tiene una entrada en la tablade procesos, un estado, un identificador, se puede decir de manera general que un proceso es una asociación de recursos generados en el sistema e importante aclarar que a diferencia del programa que es producto del programador, el proceso es producto del SO.
Hilo software:
De acuerdo al estándar POSIX, un proceso debe tener un(o más de uno) control de flujo, cada flujo de ejecución de estos es lo que se conoce como “hilo software”, entre un “hilo software” y un proceso existen diferencias importantes a remarcar. Cada proceso contiene su propio espacio de direcciones mientras que los “hilos software” comparten todos el espacio de direcciones del proceso que los ha creado. A diferencia del proceso que puede ser visto como una asociación de recursos en el sistema el “hilo software” puede ser visto como un camino de ejecución de la lógica de proceso. En el “hilo software” las operaciones de cambio de contexto y comunicación suelen ser más eficientes dado que todos los “hilos software” de un proceso comparten el mismo espacio de direcciones.
Hilo hardware:
La medida de la cantidad de tareas independientes que el hardware puede ejecutar realmente simultáneas.
Hilo software:
De acuerdo al estándar POSIX, un proceso debe tener un(o más de uno) control de flujo, cada flujo de ejecución de estos es lo que se conoce como “hilo software”, entre un “hilo software” y un proceso existen diferencias importantes a remarcar. Cada proceso contiene su propio espacio de direcciones mientras que los “hilos software” comparten todos el espacio de direcciones del proceso que los ha creado. A diferencia del proceso que puede ser visto como una asociación de recursos en el sistema el “hilo software” puede ser visto como un camino de ejecución de la lógica de proceso. En el “hilo software” las operaciones de cambio de contexto y comunicación suelen ser más eficientes dado que todos los “hilos software” de un proceso comparten el mismo espacio de direcciones.
Hilo hardware:
La medida de la cantidad de tareas independientes que el hardware puede ejecutar realmente simultáneas.
Paralelismo:
Un
sistema se dice que es paralelo si puede soportar dos o más “hilos
software” de ejecución simultáneamente, o sea si el número
de “hilos hardware” es mayor que uno.
Concurrencia:
Un
sistema se dice que es concurrente si puede soportar dos o más
“hilos software” en progreso al mismo tiempo.
El
concepto clave y la diferencia entre las definiciones de paralelismo
y concurrencia es la frase "en progreso". Una aplicación
concurrente tendrá dos o más “hilos software” en curso en algún
momento. Esto puede significar que la aplicación tiene dos o más
“hilos software” que están siendo intercambiadas por el sistema
operativo en un procesador de solo un “hilo hardware”, lo que los
intercambia como “en ejecución/suspendido” constantemente. En la ejecución en
paralelo, debe haber varios “hilos hardware” disponibles en la
plataforma de computación. En ese caso, los dos (o más) “hilos
software” podrían ser asignados a cada “hilo hardware”
separado y se ejecutarían simultáneamente. Entonces "paralelo"
es un subconjunto de "concurrente". Es decir, se puede
escribir una aplicación concurrente que utilice varios subprocesos o
procesos, pero si usted no tiene varios “hilos hardware”
disponibles, no será capaz de ejecutar su código en paralelo. Por
lo tanto, la programación concurrente y concurrencia abarcan todas
las actividades de programación y de ejecución que involucran a
múltiples flujos de ejecución implementadas con el fin de resolver
un solo problema.
En
la Fig.
1
se muestra un ejemplo de un sistema con dos tareas a
realizar(representadas
con verde y rojo),
cada una se divide en pequeñas porciones. En una maquina de dos
“hilos hardware”,
cada tarea se puede ejecutar en su propio “hilo
hardware”.
En una máquina de un solo “hilo
hardware”,
las
tareas se intercambian constantemente, ejecutando una de las pequeñas
porciones cada vez como
se muestra en la Fig.
2,
con el fin de hacer el cambio de tareas, el sistema tiene que
realizar un cambio de contexto,
y esto lleva tiempo, lo que se representa con el espaciado(en
negro),
ya que será
un tiempo empleado por el SO y que no es la tarea final que nos
interesa. Para llevar a cabo un cambio de contexto, el SO tiene que
guardar el estado del CPU (incluido el puntero de instrucciones) de
la tarea que esta ejecutando, seleccionar la tarea a ejecutar, volver
a cargar el estado del CPU para la tarea que se va a cambiar, entre otras muchas cosas
que causan demora.
 | |||
| Fig. 1 |
 | |
| Fig. 2 |
Incluso
con un sistema paralelo
es
común
tener más tareas que
“hilos hardware”,
por lo que el
cambio
de tarea se usa
incluso en
estos casos. La Fig.
3
muestra la conmutación de tareas entre las
cuatro tareas en una máquina de dos
“hilos hardware”.
 | |||
| Fig. 3 |
Según
lo que vimos las
ventajas de la concurrencia
parecen
estar acotadas por “algo”,
entonces: ¿cuándo
debemos usarla y hasta que punto? Hay
dos razones principales para utilizar la concurrencia en una
aplicación: Separación
de asuntos(separation of concerns) y rendimiento. Por lo general las demás
razones son derivadas de estas.
Se
puede utilizar la concurrencia para separar las distintas áreas
de funcionalidad, incluso cuando las operaciones en estas áreas
distintas deben ocurrir al mismo tiempo. Por ejemplo las
aplicaciones de usuario deben hacer la tarea determinada para
la que han sido creadas, pero además deben “escuchar” las
ordenes del usuario mientras hacen dicha tarea, imagine por
ejemplo un programa para grabar discos(tarea que demora) y
mientras está grabando un disco en background nos permite ir
preparando el próximo que grabaremos. En un solo hilo, la
aplicación tiene que comprobar la entrada del usuario a
intervalos regulares mientras se graba, fusionando así el
código de grabación de disco con el código de interfaz de
usuario. Si se usa concurrencia para separar estos asuntos, el
código de interfaz de usuario y el de grabación ya no tiene
por qué ser tan estrechamente entrelazados, y así estamos
reduciendo el acoplamiento :). Un hilo puede manejar la
interfaz de usuario y el otro la grabación, así que se
necesita algún mecanismo de comunicación entre ellos para si
el usuario decide por ejemplo cancelar la grabación en curso,
esto da la ilusión de la capacidad de respuesta, porque el
subproceso de interfaz le respondió de inmediato a una
solicitud del usuario. En este caso, el número de “hilos
software” es independiente del número de “hilos hardware”
disponibles, porque la concurrencia se basa en el diseño
conceptual en lugar de un intento de aumentar el rendimiento.
El
aumento de la potencia de cálculo de las máquinas con varios
“hilos hardware” no viene de correr una sola tarea más
rápido, sino de la ejecución de múltiples tareas de forma
concurrente. Antiguamente los programadores veían como la
velocidad de ejecución de sus programas aumentaba por el
simple hecho de salir nuevos procesadores al mercado, sin
ningún esfuerzo de su parte pero ahora se nos han terminado
las vacaciones ggg, si el software en verdad quiere tomar
ventaja de las nuevas generaciones de procesadores que han
salido, el software deberá ser capaz de ejecutar varias tareas
de forma concurrente. En este sentido se conocen dos maneras
principales de aumentar el rendimiento mediante concurrencia:
Concurrencia
de tareas.
Concurrencia
de datos.
El
uso de concurrencia para el rendimiento es igual que cualquier
otra estrategia de optimización: se tiene el potencial de
mejorar en gran medida el rendimiento de la aplicación, pero
también puede complicar el código, por lo que es más difícil
de entender y más propenso a errores. Por lo tanto sólo vale
la pena hacerlo para aquellas partes de rendimiento crítico de
la aplicación donde está el potencial de ganancia medible.
Tan
importante como saber cuándo y cómo usar la concurrencia es saber
cuándo no utilizarla. Intuitivamente podríamos recomendar no usar
la concurrencia cuando el beneficio no supera el costo. El código
que implementa concurrencia es más difícil de entender en muchos
casos, por lo que hay un costo intelectual directo a escribir y
mantener código concurrente, y la complejidad adicional también
puede dar lugar a más errores. A menos que la ganancia potencial de
rendimiento sea lo suficientemente grande o la separación de asuntos
lo suficientemente claras para justificar el tiempo de desarrollo
adicional necesario para hacer las cosas bien y los costos
adicionales asociados con el mantenimiento de código concurrente, no
utilice la concurrencia. En algunas
circunstancias, algunas soluciones de software y algoritmos son
mejores implementarlos usando las técnicas de programación
secuencial. En algunos casos, al
introducir la sobrecarga del
procesamiento paralelo puede afectar el rendimiento.
La concurrencia tiene
un costo. Si
la cantidad de trabajo(cómputo)
requeridos para resolver un problema secuencialmente en software es
menor que la cantidad de trabajo requerida para crear nuevos hilos
y/o procesos o menor que el trabajo requerido para coordinar la
comunicación entre las tareas que se ejecutan de forma concurrente,
entonces el enfoque secuencial es mejor.
Entonces, la
necesidad y/u oportunidad de la
concurrencia es mayormente
descubierta durante las tareas
de descomposición, más
adelante veremos
sobre esto. Para nuestro
propósito, descomposición es el proceso de dividir un proceso, un
problema o una solución en sus partes fundamentales. Algunas veces
las parte son agrupadas en áreas lógicas(que son, ordenamiento y
búsqueda, cálculo,
entrada-salida, y otras). En otras situaciones, las partes son
agrupadas como recursos lógicos(procesador, base de datos,
comunicación y otras más). Además, la ganancia de
rendimiento podría no ser tan grande como se esperaba. Conclusión,
no toda aplicación de software
requiere del procesamiento concurrente
y te insto
a notar aquí que procesamiento concurrente no implica procesamiento
paralelo como ya hemos
estado viendo.
Existen
diversos factores que afectan el rendimiento, veamos por ejemplo los
del tipo “cuello de botella”:
La ley de Amdahl(incremento de velocidad ≤
1 / [ƒ + (1 - ƒ) / p] = p / [1 + ƒ (p - 1)]; una pequeña fracción
ƒ de procesamiento intrínsecamente secuencial o no paralelizable,
limita severamente el incremento de velocidad que se puede lograr con
los procesadores p). Una tarea de una unidad de tiempo, para la cual
la fracción ƒ es no paralelizable (lo que tarda el mismo tiempo ƒ
en ambas máquinas secuenciales y paralelas) y el restante 1 - ƒ es
totalmente paralelizable [lo que se ejecuta en el tiempo (1 - ƒ) / p
en una máquina de p procesadores], tiene una duración de ƒ + (1 -
ƒ) / p en la máquina paralela.
La
Fig.4 es la gráfica del incremento de velocidad en función del
número de procesadores para diferentes valores de la fracción
intrínsecamente secuencial ƒ. el incremento de velocidad no puede
 | ||||
| Fig. 4 |
exceder
1 / ƒ, no importa que
tantos procesadores
se
usen.
Así, por ƒ = 0,1, el
incremento
de velocidad
tiene un
límite superior de 10. Afortunadamente, existen aplicaciones para
las que la sobrecarga secuencial es muy pequeña. Además, la
sobrecarga secuencial no tiene por qué ser una fracción constante
del trabajo independiente del tamaño del problema. De hecho, existen
aplicaciones para las que la sobrecarga secuencial, disminuye como
una fracción del trabajo computacional. Estrechamente relacionado
con la ley de Amdahl es la observación de que algunas aplicaciones
no tienen paralelismo inherente, lo que limita el
incremento de velocidad
que se puede lograr cuando se utilizan varios procesadores.
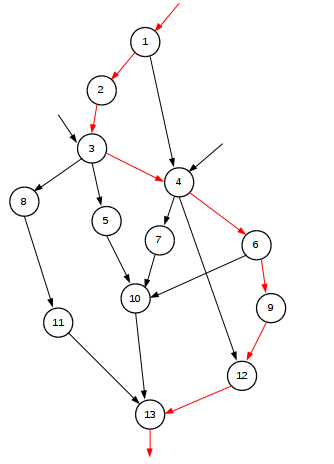 | |
| Fig. 5 |
La
Fig.
5
muestra un gráfico de tareas que
caracterizan
un procesamiento.
Cada uno de los nodos numerados en el gráfico es un procesamiento
de
unidad
de tiempo y las flechas representan dependencias de datos o los
requisitos previos de la ejecución en
cada nodo.
Un único procesador puede ejecutar las
tareas
del
gráfico
en 13 unidades de tiempo. Debido a que la ruta crítica del nodo de
entrada del 1 al nodo de salida 13 pasa a través de 8 nodos, un
procesador paralelo no lo
puede
hacer mucho mejor, ya que necesita al menos 8 unidades de tiempo para
ejecutar el grafo de tareas.
Por lo tanto, el plano de velocidad asociada con este gráfico
particular nunca puede exceder de 1,625, no importa que
tantos procesadores se usen.
Definamos
las siguientes notaciones:
p:
Número de procesadores.
W(p):
Número total de operaciones hechas por los p procesadores; esto es
también referido como trabajo computacional o energía.
T(p):
Tiempo de ejecución con los p procesadores; claramente, T(1) = W(1)
y T(p) <= W(p).
S(p):
Incremento de velocidad = T(1)/T(p).
E(p):
Eficiencia = T(1)/pT(p)
R(p):
Redundancia = W(p)/W(1).
U(p):
Utilización = W(p)/pT(p).
Q(p):
Calidad = T3(1)/pT2(p)W(p).
A
partir de esto se pueden establecer algunas relaciones:
1
≤ S(p ) ≤ p
U(p)
= R(p) * E(p)
E(p)
= S(p)/p
Q(p)
= E(p) * S(p)/R(p)
1/p
<= E(p) <= U(p) <= 1
1
<= R(p) <= 1/E(p) <= p
Q(p)
<= S(p) <= p
Ejemplo:
El
cálculo de la suma de 16 números puede ser representado por un
árbol binario(proceso de descomposición) con T(1) = W(1) = 15.
Asumamos que las adiciones consumen una unidad de tiempo e ignoremos
todo lo demás.
Con
p = 8 procesadores, tenemos:
W(8)
= 15 T(8) = 4
E(8) = 15/(8 * 4) = 47%
S(8)
= 15/4 = 3.75 R(8) = 15/15
Q(8) = 1.76
En
esencia, los 8 procesadores realizan todas las adiciones en el mismo
nivel del árbol en cada unidad de tiempo, a partir de los nodos hoja
y terminando en la raíz. La relativamente baja eficiencia es el
resultado del paralelismo limitado cerca de la raíz del árbol.
Ahora, suponiendo que las operaciones de adición que están
alineadas verticalmente en la Fig. 6 son para ser realizadas por el
mismo procesador y que cada transferencia entre procesadores que está
representada por una flecha oblicua, también requiere una unidad de
trabajo(tiempo), los resultados para p = 8 procesadores se convierten
en:
W(8)
= 22 T(8) = 7
E(8) = 15/(8 × 7) = 27%
S(8)
= 15/7 = 2.14 R(8) = 22/15 = 1.47
Q(8) = 0.39
La
eficiencia en este último caso es menor incluso, primeramente porque
las transferencias entre procesadores constituyen una sobrecarga en
lugar de una operación útil.
 | |
| Fig. 6 |
Además
de los factores de tipo “cuello de botella”, se dice que la
concurrencia “tiene un costo”, y se manifiesta principalmente
cuando es concurrencia basada en paralelismo:
Hay
una sobrecarga inherente asociado con el lanzamiento de un hilo, ya
que el SO
tiene
que asignar los recursos del núcleo asociados y espacio de pila y
luego añadir el nuevo hilo al planificador,
todo lo cual lleva tiempo. Si la tarea a ejecutar en el hilo se
completa rápidamente, el tiempo real tomada por la tarea puede ser
eclipsado
por la sobrecarga de lanzar el hilo, posiblemente haciendo que el
rendimiento general de la aplicación peor que si la tarea tenía
sido ejecutadas directamente por el hilo de devolución
de resultado.
Además, los hilos son un recurso limitado. Si usted tiene demasiados
hilos de ejecución
a la vez, estos
consumen
recursos del SO
y puede hacer que el sistema en su conjunto tenga
una ejecución
más lenta. No sólo eso, sino que el uso de demasiados hilos puede
agotar la memoria disponible o espacio de direcciones de un proceso,
porque cada hilo requiere un espacio de pila separada. Esto es
particularmente un problema para los procesadores
de 32 bits con una arquitectura plana donde hay un límite de 4 GB de
espacio de direcciones disponibles: si cada hilo tiene una pila de 1
MB (como es típico en muchos sistemas), entonces el espacio de
direcciones sería
todo utilizado con 4.096 hilos, sin permitir ningún espacio para
datos
estáticos o
para
el heap.
Aunque los
sistemas de 64-bit
(o sistemas más grandes) no tienen este límite de espacio de
direcciones directa, todavía tienen recursos finitos: si ejecutan
demasiadas condiciones de competencia,
que
implican las
secciones criticas; proteger variables, semáforos,
…, este
tiempo puede causar problemas.
Por
último, mientras más hilos que se estén ejecutando, el sistema
tiene que hacer más cambio de contexto de las operaciones. Cada
cambio de contexto toma tiempo que podría ser usado haciendo un
trabajo útil, por lo que en algún momento de la adición de un hilo
adicional en realidad reducirá el rendimiento general de la
aplicación en lugar de aumentarlo. Por esta razón, si usted está
tratando de lograr el mejor rendimiento posible del sistema, es
necesario ajustar el número de “hilos software” al número de
“hilos hardware” disponibles.
En
los posts que siguen veremos algunas técnicas para implementar la
concurrencia de forma correcta, tendremos algún ejemplo de “tareas
de descomposición”, concurrencia
basada en paralelismo, concurrencia basada en tareas y programación
funcional, sí, programación funcional en C++. Una
de las múltiples
ventajas que posee C++ como lenguaje de programación
es el hecho de soportar múltiples
paradigmas de desarrollo con
un sencillez de implementación aceptable,
a diferencia de Java por ejemplo que todo debe ser un objeto, C++
soporta programación
orientada a objetos, programación
genérica,
programación
imperativa o procedural,
programación
funcional, programación
concurrente y otros.











{kind=link}
{kind=link}